スクレイピングに挑戦
アウトプットが渋滞中
週一回の更新を目標にしていましたが、追い付かなくなってきました。
仕事の方も新しい試み(自分の中で)をやっていて、そちらも覚えるものが多く大変…。スクラムや継続的インテグレーション(CI)などなど。
ただ、今までの仕事の仕方に比べると楽しいので苦ではないですけどね。仕事を楽しいと思う日が来るとは…!
自己学習では、自分が使いたいアプリを作るために必要なスクレイピングという技術について勉強中。 その経過について書きながら、頭の中を整理したい。
スクレイピングとは
WebページのHTML構造を解析し、任意の情報を抽出する技術です。 まず第一の目標として、市の施設予約システムからテニスコートの空き情報を取得するところまで作っていこうと思います。
そこで、pythonを使ったスクレイピングに使えるライブラリは次の2つ
urllib
URLを扱うライブラリ。 主に、URLを指定してリクエストを送信し、レスポンス情報を取得します。 その情報から、HTMLの要素を取り出したりするのに使います。 ただ、urllibよりはrequestsというライブラリの方がより高水準で使いやすく、お奨めらしい。
Beautiful Soup
面白い名前のライブラリ。「ふしぎの国のアリス」の中で出てくる詩が由来らしい。今度調べてみよう…。 HTMLを渡すと解析してくれます。
とりあえずやってみる
まずは小手調べに、自分が利用しているシステムのトップページのURLを指定して「title」要素を抽出してみる。
from bs4 import BeautifulSoup import urllib.request as req # URLを指定(一応マスキング) url = "https://xxxxxxxxxxxxxxxxx" # URLを開き、レスポンスを取得 res = req.urlopen(url) # レスポンス情報からHTMLを解析 soup = BeautifulSoup(res, "html.parser") # "title"要素を抽出 title = soup.select_one("title").string print("title = ", title)
結果は↓
title = 施設予約システム
こうでました!
あとは、select_one("title")で引数として渡している「title」の部分を他の要素で指定してあげれば割とすぐできるのでは?
…この結果を得られた時はそう思っていました…。
JavaScriptの壁
抽出したい対象の要素を知るために、ターゲットとなるシステムのHTML構造を見てみます。
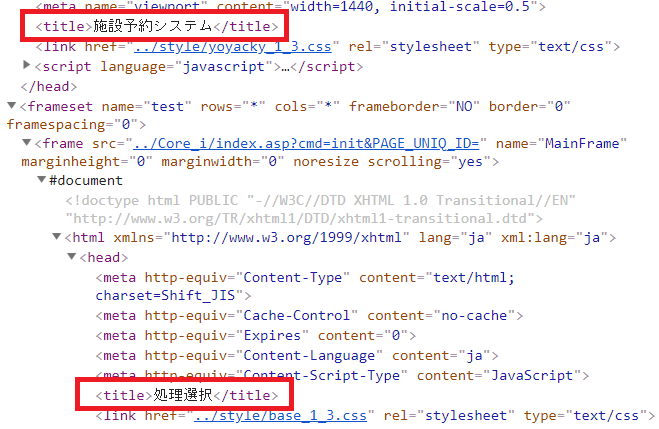
さっきは「施設予約システム」が抽出されたので、上の「title」が取れていたようです。 frame内の「title」を取るには、frame要素のsrc属性に指定してあるURIをくっつけたら良い…?
title = 表示できません
うーむ、URLをブラウザで直打ちするとタイトルが「処理選択」になるから、title要素もそうなってるハズなのに違う文字列が抽出されるのは何故だ…。
Beautifulsoupで解析した結果を以下のコードで表示して、HTML構造がどうなっているか見てみよう。
print(soup.prettify())
その結果を抜粋
<html> <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <meta content="no-cache" http-equiv="Cache-Control"/> <meta content="0" http-equiv="Expires"/> <meta content="ja" http-equiv="Content-Language"/> <title> 表示できません </title> <link href="../style/yoyacky_1_3.css" rel="stylesheet" type="text/css"/> <script language="javascript"> function Window_OnUnload(){ } </script> </head> <body bgcolor="#FFCC99" link="#000000" onunload="Window_OnUnload()" text="#000000" vlink="#000000"> </body> </html> <!--<font style="font-size:13pt;">--> <font class="SerchMiddleBold_font"> 接続が制限時間切れです。 <br/> ブラウザを閉じて処理をやり直してください。 <br/> <br/> 閉じるボタンが使用できない場合は、 <br/> ブラウザの閉じるボタンを使用して画面を閉じてください。 <br/> <input alt="この画面を閉じる" name="btn_close" onclick="window.top.close();return false;" src="../image/window_close.jpg" type="image" value="閉じる"/> </font>
表示できなかったパターンのHTMLが返ってきている。 body要素の属性にonloadでJavaScript指定してたりするから、画面操作しないとダメなんだろうか…。
JavaScriptも慣れてないから時間かけないとと厳しいなぁ。
次のアプローチ
このような場合のアプローチとして、Webブラウザ経由でのスクレイピング方法もあります。 そこで使えるのが、Webブラウザを自動操作させるSeleniumと、画面無しでコマンドラインから利用できるWebブラウザのPhantomJS!
Seleniumは今仕事でも使おうとしているし、一石二鳥! という訳でまたインプットのお時間が始まります。先は長そうだ。