pythonでDB操作
DBMSに依存しないDB操作プログラミング
SQLiteやMySQL, PostgreSQL, Oracle Databaseなど色々DBMSがあり、それぞれプログラムから使用する際はDBMS毎に異なったコーディングが必要。覚えきれない…。
そこで、オブジェクト指向マッピング(ORM)という技法を使えば、DBMS毎にコードを変える必要が無くなるのです!
pythonにはSQLAlchemyというパッケージがあり、それで実現できます。やったね!
ということで、これは是非身につけたい。
まずはSQLite用のコーディング
SQLite用に書くとこんな感じなります。
sqlite3はpythonに標準でインストールされていて、軽くて使いやすい。らしい。
import sqlite3 # DBのコネクションを生成 # :memory:を指定すると、DBがメモリ上に保存され、接続が終了すると消える。DBファイルに出力するときはファイル名を指定する。 conn = sqlite3.connect(':memory:') # DBを操作するためのカーソルを生成 curs = conn.cursor() # executeでSQLを実行 curs.execute( 'CREATE TABLE persons(id INTEGER PRIMARY KEY AUTOINCREMENT, name STRING)') curs.execute( 'INSERT INTO persons(name) values("Mike")' ) curs.execute( 'INSERT INTO persons(name) values("Nancy")' ) conn.commit() curs.execute('SELECT * FROM persons') # クエリ結果をコンソールに表示 print(curs.fetchall()) conn.close()
コンソールの表示結果は↓
[(1, 'Mike'), (2, 'Nancy')]
これがMySQLやPostgreSQLになるとまた別のパッケージをインストールして、そのパッケージの使い方に合わせたコーディングが必要。
SQLAlchemyを使ってみる
SQLAlchemyを使ってSQLiteのDBを操作するコーディングはこうなる。
import sqlalchemy import sqlalchemy.ext.declarative import sqlalchemy.orm # データベース接続のためのEngineオブジェクトを取得 engine = sqlalchemy.create_engine('sqlite:///:memory:') # Baseにオブジェクトを生成 Base = sqlalchemy.ext.declarative.declarative_base() # Baseに入ったオブジェクトのクラスを継承して、テーブルの定義クラスを作成 class Person(Base): __tablename__ = 'perons' # テーブルのカラムを定義 id = sqlalchemy.Column( sqlalchemy.Integer, primary_key=True, autoincrement=True) name = sqlalchemy.Column(sqlalchemy.String(14)) # 使用するデータベースのEngineをBaseに設定 Base.metadata.create_all(engine) # DBにアクセスするため、Engineのセッションを作成 Session = sqlalchemy.orm.sessionmaker(bind=engine) session = Session() # DBに追加するオブジェクトを作成し、セッションに追加 person1 = Person(name='Mike') person2 = Person(name='Nancy') session.add(person1) session.add(person2) session.commit() # クエリの結果全てをリストで取得 persons = session.query(Person).all() # リストの中身をコンソールに表示 for person in persons: print(person.id, person.name)
出力結果は↓
1 Mike 2 Nancy
UPDATEする時は次のように記述
# データを更新 # まずは更新対象のデータの1行目を取得 person3 = session.query(Person).filter_by(name='Mike').first() # データを書き換え、セッションに追加 person3.name = 'Michel' session.add(person3) session.commit()
ここで色々と疑問
ひとまず、使い方の流れを理解した。…が、ちょっといくつか分からないコードがある。 基礎的な話です。
分からないポイント
pythonのクラスとかその辺がまだ身に付いていない感じ。
1つ目
import sqlalchemy engine = sqlalchemy.create_engine('sqlite:///:memory:')
sqlalchemyをimportしてるんで、sqlalchemyていうモジュールがあって、その中でcreate_engine関数が定義されてるんですよね?
探してみた結果。
sqlalchemyパッケージ(フォルダ)があり、その配下のengineパッケージの__init__.pyの中に定義されていました。
つまり、普通に呼ぶときは
import sqlalchemy.engine engine = sqlalchemy.engine.create_engine('sqlite:///:memory:')
となるはず?これで実行しても同じ結果でした。
ここで気付いたのが、「あれ、importする時って、パッケージ名.モジュール名だよね?」
あー、__init__.pyだとモジュール名が省略されるということか。
なので、import sqlalchemyの一文で、sqlalchemy配下の__init__.pyが呼ばれる。
そこには
from .engine import create_engine, engine_from_config
と記述がある。
ここでengineが出てきました。でもこれはパッケージなので、またモジュール名が無い。
そして__init__.pyの中にcreate_engineがいる。
つまり、import sqlalchemyだけでその配下のengineパッケージの__init__.pyまで読み込まれるってことかー…。慣れないorz
はい、次
2つ目
Base = sqlalchemy.ext.declarative.declarative_base() … Base.metadata.create_all(engine)
この流れ…。
あるクラスのオブジェクトを生成して、そのクラスのインスタンスメソッドcreate_allが呼ばれてるんだろうか…でも間の.metadata.は何者か。
Base.metadataはBaseに入れたクラスオブジェクトで、そのインスタンス変数matadataにまたクラスのオブジェクトが入ってて
そのクラスがcreate_allを定義しているってことかな。
sqlalchemyのドキュメントで調べると、そのクラスはclass sqlalchemy.schema.MetaDataということになっているが、いない。
pythonista3アプリだと宣言箇所に飛べないから
探すのが大変…。(修行にはなりそう)
そして、sqlalchemy.sql.schemaにいたーーー!
実態はsqlalchemy.sql.schema.MetaDataでした。
なんで違うかと考えたところ、ドキュメントには「MetaData API」という文字があったんで、これはあくまでAPIとしてのマニュアルってことか。
ドキュメント上は、実態とか関係なしにモジュールの呼び出し方だけ記載してあるってことなんですねー。知らなかった。
ドキュメント(英語)ちゃんと読めって話ですが、今はまだ時間がかかりすぎると思うので、もうちょいスキル上がってから読みます! 一旦モヤモヤは落ち着いたので良しとしよう。
最後
Session = sqlalchemy.orm.sessionmaker(bind=engine) session = Session()
Sessionとsessionの違いとは…。
Sessionはクラスのオブジェクトが入ってるとして、sessionはそれをインスタンス化したものだよねきっと。
ドキュメントに
A configurable Session factory.
The sessionmaker factory generates new Session objects when called, creating them given the configurational arguments established here.
て書いてある。訳すと
設定可能なセッションファクトリ。
sessionmakerファクトリは呼び出されると新しいSessionオブジェクトを生成し、ここで設定された構成引数を与えられてそれらを作成します。
うん、それっぽい!(疲れてきた)
まとめ
なるほど、こうやってDBMSの種類に合わせたクラスの構造自体を作っていって、操作する時はその出来上がったクラスをインスタンス化して使うってことなんだなぁ。きっと。
今はそう理解しておこう…。またスキルが上がった時にさらに深掘りしたいと思います
詳しい人いたら是非指摘して欲しい!
プログラミング修行中
何にしてもプログラミング
インフラからフロントエンドまで、色々できるようになりたいとは言っても、まずはプログラミングスキルが無いと転職もできない、ということで力を入れないといけない。
アウトプットしていく
年末から時間を見つけては競技プログラミングの問題を解いていました。 数をこなすのはいいけど、自分のコードを見直したり、レベル高い人のコードと比べたりして復習の時間も必要…ということでアウトプットしながら頭の中を整理していく習慣をつける!
今回のアウトプット
競技プログラミングとは別で、Udemyで購入したシリコンバレー流のpythonコードスタイルを学ぶ!という動画も視聴進めています。そちらもかなりインプットが溜まっているので、整理整理。
CSVファイルの読み込み、書き込み
よく使いそうな処理をピックアップして書いてみます。
configファイルでcsvファイルパスを指定
configparserパッケージを使ってみます。
まずは、config.iniファイルを作成。
import configparser # ConfigParserクラスのオブジェクトを作成 config = configparser.ConfigParser() # 辞書形式でカテゴリと各要素を指定 config['CSV_FILE'] = { 'path': 'tmp/', 'name': 'counter.csv', } # config.iniファイルを新規作成し、writeメソッドにオブジェクトを渡し書き込む # ファイルのclose忘れを防止するため、withステートメントを使用している with open('config.ini','w') as config_file: config.write(config_file)
これで出来上がったconfig.iniファイルの中身が以下。
[CSV_FILE] path = tmp/ name = counter.csv
csvファイルの存在を確認、無ければ新規作成
CsvModelというクラスを作って、オブジェクト生成時に存在確認する。
class CsvModel(): def __init__(self): self.csv_file = self.get_csv_file_path() # csvファイルが存在しなかったら新規作成 if not os.path.exists(self.csv_file): pathlib.Path(self.csv_file).touch() self.header = [CSV_HEADER_NAME, CSV_HEADER_COUNT] # csvデータの格納領域を作っておく。 # (keyがない場合、int型のデフォルト値(0)が設定される、defaultdictオブジェクト) self.data = collections.defaultdict(int) self.load_data()
get_csv_file_pathメソッドでは、configparserを使ってconfigファイルの内容を読み込み、csvのパスを返すようにしている。
def get_csv_file_path(self): config = configparser.ConfigParser() config.read(CONFIG_FILE) return config['CSV_FILE']['path'] + config['CSV_FILE']['name']
また、load_dataメソッドでは、既にcsvファイルが存在していた場合、オブジェクト生成時にcsvの内容を読み込む。
def load_data(self): with open(self.csv_file, 'r+') as csv_file: reader = csv.DictReader(csv_file) for row in reader: self.data[row[CSV_HEADER_NAME]] = int(row[CSV_HEADER_COUNT]) return self.data
csvファイルにデータを書き込む
csvパッケージのDictWriterを使うと簡単!
def save(self): with open(self.csv_file,'w+') as csv_file: # DictWriterを使うと、辞書形式でcsvファイルに書き込める writer = csv.DictWriter(csv_file,fieldnames=self.header) writer.writeheader() for name, count in self.data.items(): writer.writerow({ CSV_HEADER_NAME: name, CSV_HEADER_COUNT: count })
csvファイルに書き込むデータを作成
csvのカラムNAMEを指定したら、対応するCOUNTカラムの値が増えていくメソッドを作成。
def increment(self, name): self.data[name] += 1 self.save()
ではこれを使ってcsvファイルに書き込もう!
import csvmodel csv_file = csvmodel.CsvModel() csv_file.increment('rabbit') csv_file.increment('cat') csv_file.increment('dog') csv_file.increment('rabbit')
結果は…
NAME,COUNT rabbit,2 cat,1 dog,1
できました!
動画の演習内容をもとに自分なりにカスタマイズしたけど、色々と歪な設計になってしまったような気がするorz
オブジェクト指向的なコーディングも鍛えなきゃ…。
一応、読み込みも確認のため、別のオブジェクト生成してみる。
csv_file2 = csvmodel.CsvModel() csv_file2.increment('rabbit') csv_file2.increment('cat') csv_file2.increment('rabbit') csv_file2.increment('rabbit')
↓
NAME,COUNT rabbit,5 cat,2 dog,1
あってます。
家族が増えました
全然関係ないですが、癒しのため。

スクレイピングに挑戦
アウトプットが渋滞中
週一回の更新を目標にしていましたが、追い付かなくなってきました。
仕事の方も新しい試み(自分の中で)をやっていて、そちらも覚えるものが多く大変…。スクラムや継続的インテグレーション(CI)などなど。
ただ、今までの仕事の仕方に比べると楽しいので苦ではないですけどね。仕事を楽しいと思う日が来るとは…!
自己学習では、自分が使いたいアプリを作るために必要なスクレイピングという技術について勉強中。 その経過について書きながら、頭の中を整理したい。
スクレイピングとは
WebページのHTML構造を解析し、任意の情報を抽出する技術です。 まず第一の目標として、市の施設予約システムからテニスコートの空き情報を取得するところまで作っていこうと思います。
そこで、pythonを使ったスクレイピングに使えるライブラリは次の2つ
urllib
URLを扱うライブラリ。 主に、URLを指定してリクエストを送信し、レスポンス情報を取得します。 その情報から、HTMLの要素を取り出したりするのに使います。 ただ、urllibよりはrequestsというライブラリの方がより高水準で使いやすく、お奨めらしい。
Beautiful Soup
面白い名前のライブラリ。「ふしぎの国のアリス」の中で出てくる詩が由来らしい。今度調べてみよう…。 HTMLを渡すと解析してくれます。
とりあえずやってみる
まずは小手調べに、自分が利用しているシステムのトップページのURLを指定して「title」要素を抽出してみる。
from bs4 import BeautifulSoup import urllib.request as req # URLを指定(一応マスキング) url = "https://xxxxxxxxxxxxxxxxx" # URLを開き、レスポンスを取得 res = req.urlopen(url) # レスポンス情報からHTMLを解析 soup = BeautifulSoup(res, "html.parser") # "title"要素を抽出 title = soup.select_one("title").string print("title = ", title)
結果は↓
title = 施設予約システム
こうでました!
あとは、select_one("title")で引数として渡している「title」の部分を他の要素で指定してあげれば割とすぐできるのでは?
…この結果を得られた時はそう思っていました…。
JavaScriptの壁
抽出したい対象の要素を知るために、ターゲットとなるシステムのHTML構造を見てみます。
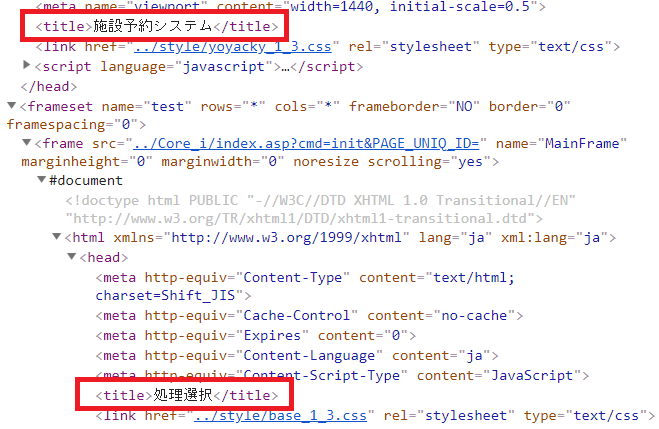
さっきは「施設予約システム」が抽出されたので、上の「title」が取れていたようです。 frame内の「title」を取るには、frame要素のsrc属性に指定してあるURIをくっつけたら良い…?
title = 表示できません
うーむ、URLをブラウザで直打ちするとタイトルが「処理選択」になるから、title要素もそうなってるハズなのに違う文字列が抽出されるのは何故だ…。
Beautifulsoupで解析した結果を以下のコードで表示して、HTML構造がどうなっているか見てみよう。
print(soup.prettify())
その結果を抜粋
<html> <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <meta content="no-cache" http-equiv="Cache-Control"/> <meta content="0" http-equiv="Expires"/> <meta content="ja" http-equiv="Content-Language"/> <title> 表示できません </title> <link href="../style/yoyacky_1_3.css" rel="stylesheet" type="text/css"/> <script language="javascript"> function Window_OnUnload(){ } </script> </head> <body bgcolor="#FFCC99" link="#000000" onunload="Window_OnUnload()" text="#000000" vlink="#000000"> </body> </html> <!--<font style="font-size:13pt;">--> <font class="SerchMiddleBold_font"> 接続が制限時間切れです。 <br/> ブラウザを閉じて処理をやり直してください。 <br/> <br/> 閉じるボタンが使用できない場合は、 <br/> ブラウザの閉じるボタンを使用して画面を閉じてください。 <br/> <input alt="この画面を閉じる" name="btn_close" onclick="window.top.close();return false;" src="../image/window_close.jpg" type="image" value="閉じる"/> </font>
表示できなかったパターンのHTMLが返ってきている。 body要素の属性にonloadでJavaScript指定してたりするから、画面操作しないとダメなんだろうか…。
JavaScriptも慣れてないから時間かけないとと厳しいなぁ。
次のアプローチ
このような場合のアプローチとして、Webブラウザ経由でのスクレイピング方法もあります。 そこで使えるのが、Webブラウザを自動操作させるSeleniumと、画面無しでコマンドラインから利用できるWebブラウザのPhantomJS!
Seleniumは今仕事でも使おうとしているし、一石二鳥! という訳でまたインプットのお時間が始まります。先は長そうだ。
Web画面の作り方
フレームワークの流れ
覚えたこと。 DjangoでのWebアプリ画面の作り方。
templatesディレクトリ配下にWeb画面の基礎部分となるhtmlファイルを作成する。htmlファイルに対するhttpリクエストの対応を
view.pyに記述する。対象のhtmlファイルが呼ばれる際のURLパターンを
urls.pyに記述する。
htmlファイル
記述としては↓のような感じ。(body部を抜粋)
<body> <form action="" method="POST" > {% csrf_token %} <p>記号<br> <select name="suit"> <option value="H">Heart</option> <option value="D">Dia</option> <option value="S">Spade</option> <option value="H">Clov</option> </select> </p> <p>数字<br> <select name="rank"> {% for i in rank_list %} <option value={{i}}>{{i}}</option> {% endfor %} </select> </p> <p> <input type="submit" value="送信"> </p> </form>
画面はこうなる。
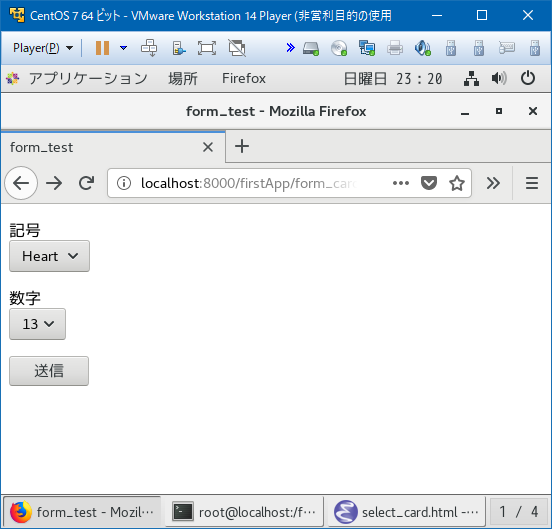
通常のhtmlの記述に加えて、{% %}で囲まれた部分にDjangoが用意したpythonっぽいロジックを記述できたり、view.pyとの変数のやり取りができたりします。
なお、templatesディレクトリ自体をDjangoが認識するために、setting.pyに今回作成したアプリの情報を記載する必要がある。
INSTALLED_APPS = [
'firstApp', #←これ#
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
view.py
記述はこんな感じ。
def form_card(request): if request.method =='GET': rank_list=[] for i in range(1,14): rank_list.append(str(i)) dictionary = {'rank_list':rank_list} dictionary.update(csrf(request)) return render(request, 'select_card.html', dictionary) if request.method == 'POST': suit = request.POST['suit'] rank = request.POST['rank'].zfill(2) dictionary = {'suit':suit, 'rank':rank} print(suit,rank) return render(request, 'display_card2.html', dictionary)
form_card関数が呼ばれたら、この処理が動く。
最終的にはrender関数で遷移先のhtmlファイルを決定し、dictionaryの部分にhtml内で使用する変数などなどを格納して受け渡しする。
ちなみに、dictionary.update(csrf(request))はDjangoが用意してくれているセキュリティ対策で、CSRF(クロスサイトリクエストフォージェリ)という攻撃を防ぐ機能を準備してくれている!
フレームワークって…いいね…。
urls.py
正規表現を使って、URLのパターンと、呼び出す関数の紐づけを行う。
urlpatterns = [
url(r'^form_card/$',views.form_card),
]
ここで記述する関数名と、view.pyに定義した関数名が違って何度もDjango先生に怒られました…。そして削られていく時間。
ちなみに送信ボタン押すと
対応するトランプのカードが表示されます。
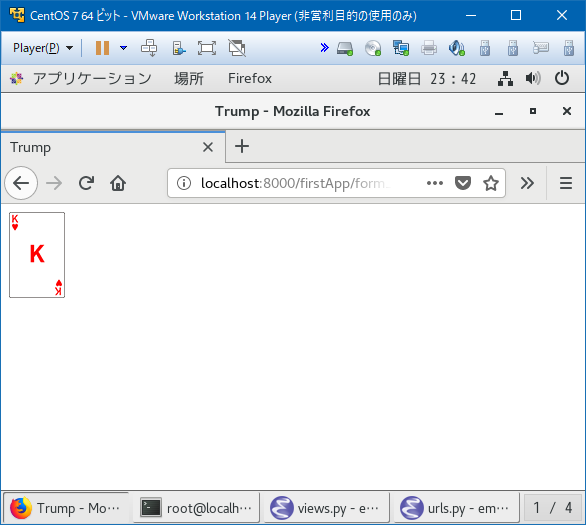
画面作成の基本的な流れはこんなところですかね。 次はDjangoでデータを保管したりする動作を覚えて、最後にブラックジャックを動かす!
…もうちょっと進めるペース上げたいけど、8月、9月は誘惑が多くて更に時間が削られることが想定されます。
- 8月~9月末までの誘惑
- 9月末~の誘惑
これらの壁をどう乗り切って行くかが鍵。 目標を見失わないようにせねば。
Djangoに触れてみる
再スタート
ひとまず心のモヤモヤも晴れ、やっと本筋に戻ることができました。心なしか、以前よりテキスト読みやすくなった気がします。
たぶん気のせい。
仮想OS上でWebサーバを動かす
閑話休題(使ってみたかっただけ)
3週間も経ってどこまでやったかあやふやですが、確かWin10のPC上の仮想マシンにCentOS7をインストールするところまでやっていました。
Webサーバソフトをインストール
CentOSにWebサーバ機能を持たせます。 Webサーバといえば、apacheが有名で、今読んでいるテキストもそれを導入しています。
しかし最近はnginx(エンジンエックス)というソフトが普及してきているらしく、今後主流になりそうなので、こちらを入れてみました。
apacheには「C10k問題」という、1つのWebサーバにクライアントが1万台接続すると、動作が重くなってしまう問題があります。
その点nginxは軽量でかつ1つのプロセスで複数のリクエストを処理する「イベント駆動モデル」であり、クライアント台数が1万台を超えても余裕で動く。
…という特徴があるので、ユーザ数が多いWebシステムにおいて利点があります。
そんなでかいシステム作れませんが、流行りに乗っておきたい。
インストール自体は簡単で、CentOSに含まれているyumコマンドで一発!
- rootユーザで、
/etc/yum.repos.d/nginx.repoファイルを作成し、以下の内容で保存。これで、yumコマンドで参照するリポジトリが追加される。[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/mainline/centos/7/$basearch/
gpgcheck=0
enabled=1
- そして、
yum install nginxコマンドを実行!終わり! - 一応、バージョン確認コマンド
nginx -vで、インストール成功しているのを確認。
やっとDjango
やっとDjango(ジャンゴ)に戻ってきました。 Webサーバの準備はできたので、そこに乗せるWebアプリを作っていきます。
pythonをインストールした際についでに入っているpipツールでDjanoをインストールできました。yumのpython版ってところですかね?
プロジェクト作成
ここから、Webアプリ開発に便利なフレームワークを使っていきます。
django-admin startproject プロジェクト名のコマンドでプロジェクト用ディレクトリが作成され、その中に部品達が生成されます。
中でもmanage.pyというpythonファイルの部品が、アプリを作るための各種雛形ファイルを作ってくれたり、開発用の簡易サーバを起動したりしてくれるみたいです。
python manage.py runserverでサーバ起動。(ポートは8000番)python manage.py startapp アプリ名でアプリ用雛形作成。
Webアプリ用の雛形ファイル
主要なものをメモメモ。
view.py
画面に何を表示させるか、どんな処理をするかを記述する。
apps.py
アプリケーションの設定を記述する。
models.py
データベース関係のファイル。
admin.py
管理画面の設定を記述する。
urls.py(これは自作)
URLと、呼び出される処理の関係を記述する。
今週はこんなところ。
今後の予定
今読んでいる本をマスターするまでは、と思っていましたが衝動買いしてしまった。

以前の投稿で書いた、直近で欲しいアプリを作るための技術「スクレイピング」(Webサイトのデータを取得するもの)について記述があったのでつい…。
積み本が増えないように早く進めなければ…。
pythonコーディングひと段落
次はWEBアプリ
さて、プログラミングの方も、ちまちま進めています。 前回紹介した本の、ブラックジャックをpythonで作るところまでは完了です。
とはいえ、コマンドラインのみで動く簡単なものですが。

[ H 7 ]とか[ D 5 ]というのは、それぞれハートの7、ダイヤの5といった表記です。
モヤっとコード
このプログラムはfor文やif文、リスト等が分かっていればすぐに作れるので、あまり躓くことはありませんでした。
関数についても、メインのモジュールに関数を直書きして、メイン関数の中で使う、という流れ。
クラスを作ってインスタンス化→インスタンスメソッドを使う、といった処理は無かったため、物足りない感じ…。
(クラスメソッドとかスタティックメソッドとかがまだ腹落ちしていないので…次の課題ですね)
そんな中でも、ちょっとモヤっとするコード(完全にマスターしたとは言い切れないもの)があったのでメモ。
いわゆるリスト内包表記
#デッキを作る
def make_deck():
rank = range(1,14)
suit = ('S','H','C','D')
deck = [(i,j) for i in rank for j in suit]
random.shuffle(deck)
return deck
deck=[(i,j) for...の部分ですね。
(i,j)というタプル(要素を変更できない配列)のリストを生成しています。
rankが1から13までfor文で回る間、それぞれS,H,C,Dがfor文で回る二重ループの表記。これで全ての組合せのリストとなっています。
こういうのサラっと書けるようになりたい。
複数の戻り値を格納
#勝敗の結果を判定
message, player_money = win_lose(dealer_hand, player_hand, bet, player_money)
print(message)
win_loseという関数で勝敗が確定し、表示する文字列と所持金の増減値を返します。
それらをそれぞれ、messageとplayer_moneyに格納しています。
これは便利ですが…その関数が何をどの順番で返してくるのか、注意しないとすぐにバグ化する予感。
そしてDjangoへ
ついつい心の中で「ディージャンゴ」って呼んじゃいますが、「ジャンゴ」なんですよね。なぜだ。
ここでWEBアプリを動かす為のサーバが必要になるのですが、現在はその環境を構築中です。
自宅にあるWindows10のノートPC上に、CentOS7の仮想サーバを構築し、そこにDjangoを乗せて見ようと思っています。
CentOS
Linuxを基本にしたOS(ディストリビューション)の1つ。いくつかある中で、結構メジャーに使われているらしい。これも使いながら勉強していきましょう…。
参考
所感
Djangoへの道のりはもうちょっと長かっ た…。
小さな一歩
プログラミングの勉強開始!
2回目の更新です。今回はプログラミングの話。
初回のブログに書いた通り、pythonという言語を勉強して最終的に何かアプリを作りたいと思ってます。
まだどんなことが出来るか分かってませんが、自分が使いたくなるものを自分のために作る!…というモチベーションでやって行く。
ちなみに今直近で欲しいものは…
市営テニスコート予約(補助)+管理
ができるアプリです。
なぜなら、今利用している市の施設予約システムがとても不便だから。
その理由は
- レスポンシブでない。 (スマホで見辛い…pc起動したくない)
- 一昔前のUIで使いづらい。 (期間を範囲指定して空いている日を一括で見たい…)
- 管理画面見ても、いつ抽選が実施され予約確定になるのか分からない。
などなど。
なんかこう、アプリで指定した条件で、市のシステムにリクエスト投げてその結果をアプリで受ける、みたいなのが作れたら後は自分向けのUIにしたり。
また、その予約情報をLineとかでシェアできるようにして参加者への連絡の手間を減らすとか出来たらいいなぁ!(そういうの既にあったら教えてください…使いたい!)
パパ友とのテニスが捗る。
入門書を買いました
とりあえず基本的な文法とかは↓のサイトで勉強しています。
■Python-izm | Python の入門から応用までをサポートする学習サイト
他にもWeb上で勉強できることはありますが、何か手元にひとつバイブル的なものが欲しいのと、何かアプリを作りながら進められるものが無いかと。その方が理解が深まりますからね。
そう思い立ち、先週、池袋ジュンク堂で色々眺めていたところ良さそうな本があったので、買いました。

この本で学べること
今コードを書きながら読み進めているところですが…軽く内容を紹介します。
pythonの基礎
どの本でもまずはここから。
pythonのインストール方法、基本的な文法、プログラムの実行の仕方…。
電子書籍もいいですが、文法なんかは紙の本ですぐにページめくって確認できた方がいいですよね。
pythonでブラックジャックのゲームを作る
実際にトランプゲームを作りながら、pythonに慣れることができます。(まだやってないので、そう信じています)
WEBアプリを作る
前段で作ったブラックジャックをWEBブラウザ上で遊べるようにすることで、WEB開発のスキルを身につける。
WEBサーバも構築が必要になりますが…それを簡単に作るためにDjangoというWEBアプリのフレームワークを使うようです。
こいつをインストールすれば、簡単にサーバを立てられる!便利!
ブラックジャックのディーラーに人工知能を導入
プレイヤーの入力(戦略)を人工知能に機械学習させ、ディーラーがその戦略に従うようになる…と。なんか凄そうでかなりワクワクしますね!
学びたかったディープラーニングにも触れられている点もGOOD!
実際に人工知能のプログラミングまではやらず、既に出来上がっているモジュールを導入するだけのようですが、考え方は載っています。
ちなみに、使われているライブラリは以下の通り。
Numpy
数値計算ライブラリ。
高度な数学関数、ベクトル計算を正確かつ高速にできる。
Theano
数値計算ライブラリ。
数式そのものから解法を考えてくれる。
Numpyよりも最適な計算方法を編み出してくれる特徴がある。
Keras
ディープラーニング用のモジュールを含んだライブラリ。
ディープラーニングの基礎となるニューラルネットワークの構成を上手いことこう…やってくれるらしい。まだよくわかりません…要勉強orz
Pandas
データ処理をするためのライブラリ。
簡単にデータの検索、変更ができる。
7月中にはマスターしたい
本って色々買って手を出したくなるけど、まずは1冊をとことんやることが大事って偉い人が言ってた。
そして自分が理解したことを、自分の言葉で説明できるよう腹落ちさせることが重要です。
それが、このブログの目的でもあります。
時には間違った理解を書いてしまうこともあるかも知れません…そんな時はどんどんコメントでツッコんで頂けると助かります!