Kubernetesを構築しながら理解を深めてみる
あえてツールを使わない

久々に来たらボードに何か書いてある!?
Kubernetesをインストールツール使わずに構築するチュートリアルのことみたいだね…
便利なツールとかクラウドサービスとかあるのに〜
まぁ、構成を理解するために結構オススメらしいし、やってみるか…できるか不安だけど
この記事の目的
kubernetes-the-hard-wayを実施しながら、Kubernetesの構成要素を理解する。
勉強中のため、記載した内容については後日訂正する可能性もあります。
Hard Wayのゴール
最終的に↓の構成を作ることになるらしいよ
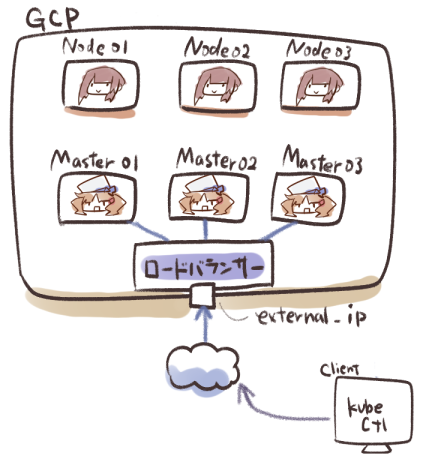
サーバ6台も立てるの!?
Masterサーバを冗長化させて、Nodeも3つに分散する感じだね
そして最後にkubectlからリソースを登録して、Pod作成と外部からアクセスできることを確認するよ
なるほど…でもドキュメントが英語で読むの時間かかりそー…
和訳してくれてるサイトとか結構あるみたい
たすかる!
ハンズオン!
準備するもの
ここでは構築に使うGoogleCloudPlatformのCLIと、複数台のサーバに同時にコマンドを打てたりするtmuxのインストールが紹介されてるね
無料トライアルで約3万円分もクレジットもらえてお得ね!
今回のハンズオンでだいたい↓くらい使いました。
作業PCで使うツールを準備
Kubernetesのクラスタ内のセキュリティを強化するために、公開鍵基盤を作るツールと、kubectlを作業PCにインストールするよ
公開鍵…なんとなーくわかるけど、すぐ忘れちゃう…
あとでまた出てくるから、そこで整理しよう
クラウドでVMとか作成
Provisioning Compute Resources
クラウド内に閉じたネットワーク(VPC)を作って、そこにVMを6台立てるよ。あとはファイアーウォールの設定したり、外部公開用のIPを取得したり。
Node用のVMにpod-cidrっていうメタデータ?が設定されてるの何!?
あとで使うらしいけど、Podを割り当てるためのサブネットなんだって
あ、そーいえばPodにもIPが振られるんだっけ
TLS証明書を作りまくる
Provisioning a CA and Generating TLS Certificates
きた…
Kubernetesのコンポーネント間で認証/認可を行うために、それぞれのコンポーネント用にTLS証明書を作成するよ
配置ミスったらアウトだねー…今回はコマンド通り打てば問題ないけど!
Kubeconfigファイルを作成
Generating Kubernetes Configuration Files for Authentication
ここもひたすらコンポーネント毎に設定ファイルを作ります
また…
この設定で、各コンポーネントが接続する先のクラスタと、使用する認証情報の組み合わせ(Context)を定義するんだ
データの暗号化設定
Generating the Data Encryption Config and Key
Kubernetesはデータ扱うためのConfig & Strageリソースがあって、その中で暗号化機能を提供しているSecretのための暗号化鍵を作成するよ
Config & Strage系は(このブログで)まだやってなかったんで、一応マニフェスト貼りますか…
kind: EncryptionConfig apiVersion: v1 resources: - resources: - secrets providers: - aescbc: keys: - name: key1 secret: ${ENCRYPTION_KEY} - identity: {}
secretリソースに対する暗号化の設定…ってカンジかな?
この設定をした上でSecretリソースを作成すると↓のようにデータが暗号化される
$ kubectl create secret generic kubernetes-the-hard-way --from-literal="mykey=mydata" -o yaml --dry-run apiVersion: v1 data: mykey: bXlkYXRh #暗号化されたデータ kind: Secret metadata: creationTimestamp: null name: kubernetes-the-hard-way
ちなみにdry-runオプションと-o yamlを組み合わせると、作成されるマニフェストを標準出力できて便利!
etcdを起動
Bootstrapping the etcd Cluster
APIサーバに送られた各リソースは、このetcdっていうデータストアに登録されるんだ
Master3台で冗長化するから、3台分のインストール作業がいるね
Masterのコンポーネントを起動
Bootstrapping the Kubernetes Control Plane
Kubernetes API Server、Scheduler、ControllManagerをインストールしていくよ
作っておいた各設定ファイルを移動して、バイナリをDL、systemdのユニットファイルを作る、という流れだね
ユニットファイルの起動コマンドのオプションがえげつない…
細かい内容はリファレンス見るしかない…
あとはロードバランサーのヘルスチェックを有効にするためにnginxを設定してるのと、APIサーバから各Nodeのkubeletへのアクセス認可設定をしているね
ClusterRoleリソースで権限を作成して、ClusterRoleBindingリソースで権限を付与する対象を決めてるよ
apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:kube-apiserver-to-kubelet rules: - apiGroups: - "" resources: - nodes/proxy - nodes/stats - nodes/log - nodes/spec - nodes/metrics verbs: - "*"
このresourcesに対して、verbsに指定した操作が可能になる…と
「*」だから全ての処理を実行できるってワケね!
apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: system:kube-apiserver namespace: "" roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:kube-apiserver-to-kubelet subjects: - apiGroup: rbac.authorization.k8s.io kind: User name: kubernetes
これで権限が「kubernetes」ユーザに紐づく。APIサーバはこのユーザでkubeletに対して認証できるようになるよ
Nodeのコンポーネントを起動
Bootstrapping the Kubernetes Worker Nodes
KubeletとKubeproxyのインストールだね。KubeletはAPIサーバからの要求でContainerdっていうサービスを介してPodを作成するみたい。Docker的なやつだね
もっと厳密に言うと、Containerdが指示を出してruncってやつがPodを作ってるらしい…
深すぎてわけわからんですね…ググりましょう…
クライアントからkubectlできるようにする
Configuring kubectl for Remote Access
クライアントにkubeconfigの設定をして、Contextをセット〜♪
Podへのルーティングを設定する
Provisioning Pod Network Routes
この時点だとPodから他ノードPodへの通信ができないから、ルートを設定するよ
DNSを立てる
Deploying the DNS Cluster Add-on
Pod名でアクセスできるよう、DNSを構築するよ
このアプリはPodで動くんだー!なんかやっとkubernetesっぽくなってきた
テストして環境削除
色々動作確認して、終了です!!
やっと動いたのに〜!?
おわり
マンガっぽくKubernetesを勉強してみる②
Kubernetesを動かす

甘いもの食べてアタマ休ませたいよ〜
…こほん。今ギャルちゃん(API)がお菓子(リソース)を持ってきて、わたしが食べ(登録)たら仕事し始めたように、Kubernetesも同じような動きをするよ
なんとっ!?
この記事の着地点
Kubernetesを動かすための基本的な操作、全体像を理解する。
勉強中のため、記載した内容については後日訂正する可能性もあります。
Kubernetesの基本的な操作
前回、Kubernetesの全体構成を図に描いてみたけど、Master Nodeにいるkube-apiserverにyml登録の指示をしていたね
クライアントにいるkubectlで登録するんですよねー
そう。実際には、ymlに書かれたリソース情報をAPI経由でMasterに登録しているんだよ
じゃあわたしたちはymlの書き方と、kubectlの使い方が分かればOKってことね♪
kubectlでもいいし↓でAPIの仕様を見て、直接プログラムに組み込んで登録することもできる
リソースの種類について
リソースは大きく分類すると5種類あるみたい。今時点の理解はこんな感じかな…
Workloadsリソース
コンテナ起動のためのリソース
Discovery & LBリソース
コンテナへのルーティング、ロードバランシングのためのリソース
Config & Storageリソース
各種設定、データ格納のためのリソース
Clusterリソース
セキュリティ、CPU/メモリ割り当てのためのリソース
Metadataリソース
コンテナ制御のためのリソース
こんなにたくさん…まぁ色々やってくれるんだから仕方ないかぁ…
開発者が特に気にするのは上の3つらしいよ。下2つはより運用的な話かな…
でもそれぞれymlで定義するんだから、一回作っちゃえば流用もしやすいはず!
未来のわたしのため…がんばるっ
動作確認環境について
言ってなかったけど、今回の勉強は↓の書籍をバイブルにして、自分なりに理解しやすい順番・言葉で表現しています
仕組みだけでなくノウハウがギッシリ詰まった本なので、全てを網羅することは無理ですが…
")
Kubernetes完全ガイド (impress top gear)
- 作者: 青山真也
- 出版社/メーカー: インプレス
- 発売日: 2018/09/21
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
サンプルコードなどはこちらから抜粋させてもらいます♪
それと、今回はKatacodaのプレイグラウンドを利用してブラウザ上で確認しています
Kubernetes Playground | Katacoda
プレイグラウンドだと、Masterと1つのNodeが初めから準備されているね
# Master Node master $ kubectl get nodes ---- NAME STATUS ROLES AGE VERSION master Ready master 94m v1.14.0 node01 Ready <none> 93m v1.14.0
Nodeからだとkubectlコマンドエラーになる…なんでだろ
# Node
node01 $ kubectl get nodes
----
The connection to the server localhost:8080 was refused - did you specify the right host or port?
APIを実行するには、Masterの接続先情報と、認証情報が必要だからね。 今はMasterから実行できるし、いったん後回しにしよう
リソースを登録する
まずは基本的な操作で、ymlファイルからリソースを登録してみよう。ちなみに ymlファイルのことをKubernetesではマニフェストっていうらしいよ
この内容を実現します!っていうカンジ?笑
apiVersion: v1 kind: Pod metadata: name: sample-pod spec: containers: - name: nginx-container image: nginx:1.12
Podっていう種類のリソースっぽい?あ、dockerイメージも書いてある!
そう、PodはWorkloadsリソースの最小単位で、コンテナが1つ以上あるグループみたいなものかな。ここではnginxのコンテナをPodとして登録するよ
マニフェストからリソースを操作するためのコマンドは次の3つ
① 新規作成 kubectl create
② 更新 kubectl apply
③ 削除 kubectl delete
master $ kubectl apply -f sample-pod.yml
----
pod/sample-pod created
新規なのに、applyコマンド?
applyは、前回の差分を抽出して更新するんだけど、リソースが登録されてなかったら新規作成してくれるから、こっちのほうが推奨されてるんだ
な、なるほど〜?あ、Podも起動してるっぽい!
master $ kubectl get pods ---- NAME READY STATUS RESTARTS AGE sample-pod 1/1 Running 0 13s
Kubernetesで簡単なコンテナ構成を組んでみる
現状確認
まだPodが配置されただけで、通信も何もできない状態だね
そういえばDockerのときも同じだったね…ポートフォワード?
ローカルホスト宛の通信をポートフォワードするやり方もあるけど、Kubernetesはコンテナオーケストレーションツールだからね。 各Podに対してロードバランシングするためのリソースを作る必要があるんだ
ちなみに、今のリソースの全量はkubectl get allで見れるよ
master $ kubectl get all ---- NAME READY STATUS RESTARTS AGE pod/sample-pod 1/1 Running 0 4m23s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 54m
ClusterIPっていうのがある…Podはさっき作ったやつだけど何だろ?
serviceっていうのがDiscovery & LBリソースの一つで、ロードバランシングをしてくれるやつだよ。 ClusterIPってのはそのServiceリソースのタイプのひとつなんだ
このservice/kubernetesってやつは、デフォルトで作られてるAPI接続用のServiceリソースみたい
Workloadsリソースでコンテナを配備
ということで、まずはPodを3つくらい作って動きを見てみようか
1個だと分からないもんね♪
ReplicaSetとDeployment
ReplicaSetリソースで、コンテナの複製(レプリカ)を作れるよ
コンテナのスケーリングってやつだね!
apiVersion: apps/v1 kind: ReplicaSet metadata: name: sample-rs spec: replicas: 3 selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.12 ports: - containerPort: 80
長くなってきた…あ、でもtemplateのspecは見覚えある!
そう、Podと同じだね。今回はコンテナのポートとラベルを書き加えてるけど
そのレプリカを3つ作るってことね!じゃあさっそくkubectl applyで…
…と思ったけどやっぱりこっちのマニフェストで作ろう!
apiVersion: apps/v1 kind: Deployment metadata: name: sample-deployment spec: replicas: 3 selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.12 ports: - containerPort: 80
ええナゼっ!?…ってあれ、あまり変わらないような…リソースの種類が違う?
これはDeploymentリソース。ReplicaSetを管理して、コンテナのアップデートをサービスに影響無いよう、徐々にやってくれたり ロールバック出来るようになるんだ。
おぉ〜!これ一つでPodもReplicaSetも作れるなら、ラクチンでイイね♪
# Deploymentリソースを作成 master $ kubectl apply -f sample-deployment.yml ---- deployment.apps/sample-deployment created # podをsample-appラベルで絞って一覧表示 master $ kubectl get pods -l app=sample-app ---- NAME READY STATUS RESTARTS AGE sample-deployment-6cd85bd5f-f2v8h 1/1 Running 0 17s sample-deployment-6cd85bd5f-q9mtr 1/1 Running 0 17s sample-deployment-6cd85bd5f-xbl5x 1/1 Running 0 17s
サクッとできた!
コンテナが落ちると、マニフェストで指定したレプリカ数に戻るよ。試しにPod1つ削除してみよう
# 指定したPodを削除 master $ kubectl delete pod sample-deployment-6cd85bd5f-f2v8h ---- pod "sample-deployment-6cd85bd5f-f2v8h" deleted # 一覧表示 master $ kubectl get pods -l app=sample-app ---- NAME READY STATUS RESTARTS AGE sample-deployment-6cd85bd5f-q9mtr 1/1 Running 0 119s sample-deployment-6cd85bd5f-xbl5x 1/1 Running 0 119s sample-deployment-6cd85bd5f-xqbds 1/1 Running 0 35s
新しい名前のPodが1つ増えてるね、すっごい!

その他のWorkloadsリソース
Deploymentリソースさえ使えればカンペキかな!?
Workloadsリソースは他にもいくつかあるよ。特定の用途で使い分けが必要だね。
DaemonSetリソース
各ノードに1Podづつ配置したい場合に利用。1PodなのでReplicaは設定できない。
StatefulSetリソース
データベースなど、永続化データボリュームの利用が必要場合に利用。
Jobリソース
1度だけの処理を実行し、コンテナが終了するような場合に利用。
CronJobリソース
Jobを定期的に作成したい場合に利用。
Discovery & LBリソースでコンテナ疎通
じゃあ次はコンテナに外部からアクセスできるようにしていこう。
Serviceリソース…だっけ?
Discovery & LBリソースには、L4ロードバランシングをするServiceリソースと、L7ロードバランシングをするIngressリソースがあるよ。
(L4とL7ってなんだ…ググろ…)
ロードバランサー(L4)とL7ロードバランサー(Pulse Secure Virtual Traffic Manager)の違いを教えてください | ニフクラ
ClusterIPとExternalIP
ちなみに今の状態でも、コンテナ間のネットワークは作られてて、お互いに通信は出来るんだ
# Pod情報を確認 master $ kubectl get pods -o custom-columns="NAME:{metadata.name}, IP:{status.podIP}" ---- NAME IP sample-deployment-6cd85bd5f-q9mtr 10.44.0.2 sample-deployment-6cd85bd5f-xbl5x 10.44.0.3 sample-deployment-6cd85bd5f-xqbds 10.44.0.1 # Podのターミナルを開く master $ kubectl exec -it sample-deployment-6cd85bd5f-q9mtr /bin/bash # 確認用にcurlをインストール root@sample-deployment-6cd85bd5f-q9mtr:/# apt-get update && apt-get install -y curl # 1個めのPodから2個めのPodにリクエスト(curlコマンドでHTTPリクエスト結果コードのみを表示) root@sample-deployment-6cd85bd5f-q9mtr:/# curl -s http://10.44.0.3:80 -o /dev/null -w '%{http_code}\n' ---- 200
200は成功レスポンスだから…ホントだ!でも外からは接続できない、ってことよね?
そう。それにPodのIP指定でしか接続できないし、ロードバランシングもしてくれないんだ。 そんな時に使うのが、Serviceリソースだよ
マニフェストはこんな感じ
apiVersion: v1 kind: Service metadata: name: sample-clusterip spec: type: ClusterIP externalIPs: - 172.17.0.65 ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 80 selector: app: sample-app
ここでClusterIPが出てくるのね!
ClusterIPは、Kubernetesクラスタ内部のネットワークで疎通が出来る仮想IPだよ。この場合 sample-clusteripに8080番ポートで接続が来たら、sample-appラベルがついたPodの80番ポートに分散される
externalIPってのもある…これは何のIPだろ?
これはNode自体のIPで、externalIPとして書くとNodeに対する接続をPodに転送することができるんだ
# NodeのIPアドレスを確認 master $ kubectl get nodes -o custom-columns="NAME:{metadata.name}, IP:{status.addresses[].address}" ---- NAME IP master 172.17.0.39 node01 172.17.0.65 # Nodeに対してHTTPリクエスト master $ curl -X GET http://172.17.0.65:8080 -o /dev/null -w '%{http_code}\n' ---- % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 612 100 612 0 0 282k 0 --:--:-- --:--:-- --:--:-- 597k 200
これでようやく、外部からコンテナに通信できるってワケね!

そう!ちなみにClusterIPだと、転送元にしたいNode分のIPを書く必要があるけど、 全てのNodeに対して転送させたい場合は、NodePortタイプがあるよ
その他のServiceタイプ
むむ…色々種類があるのね…アタマが混乱するぅ〜
他にもServiceリソースのタイプとしては↓があるけど、Discovery & LBリソースの基本はこんなところかな
LoadBalancerタイプ
Kubernetesクラスタ外部のLoadBalancerサービスから疎通できる仮想IP
Headlessタイプ
ロードバランシングでなく、クラスタ内DNSから順次PodのIPを返すタイプ(DNSラウンドロビン)
ExternalNameタイプ
外部ドメイン宛のCNAME(ドメインの別名)を返すタイプ
つづく!
マンガっぽくKubernetesを勉強してみる①
Dockerができないこと

それはどういうこと…?
Dockerが得意なのは、1つのホストでコンテナを動かすことなの
ふむふむ?(服が戻っている…)
イメージやコンテナ自体をexportして、他のホストに持っていくことは出来るんだけど、 それぞれで動いてるコンテナの状態管理とかは苦手なんだ
それぞれのサーバでdockerコマンド打つ必要があるね…数が増えるとメンドそう
そこで、コンテナオーケストレーションっていうやり方があって、 googleが作ったKubernetesというOSSが主流になってるよ!
Kubernetesを使うと、コンテナの一元管理に加え、コンテナのスケーリングやデプロイ、アップデートを自動化できる。
さっきの丸いのはこれのマークだったのね!
この記事の目的
OSSのKubernetesを理解するための勉強を目的とする。
勉強中のため、記載した内容については後日訂正する可能性もあります。
Kubernetesができることざっくり
ところでコンテナおーけすとれーしょんってなに…
コンテナを使ったシステム運用を自動化できるってことだね。 VMでいうと、負荷分散したり台数増やしたり、サーバ落ちたら再起動したり
そして何より良いのが、そういう自動化の定義をymlファイルに記述して管理できる!
おおー!でたymlファイル!つまりこれも使い回せる?!
そうそう!…という訳で楽するために、2人で勉強しよう♪
ええっ!?(システム運用とかまだやる予定ないんですけど…)
ひとまずKubernetesができることを絵に描いてみたよ

スケーリング/オートスケーリング
イメージからコンテナを複製して、負荷分散や耐障害性をアップさせる。
また、コンテナの増減を自動で行う。
スケジューリング
コンテナをサーバに配置する。配置の条件を色々設定可能。
セルフヒーリング
コンテナのプロセスが落ちたりサーバに障害が発生しても、コンテナを自動復旧する。
リソース管理
サーバリソース状況に合わせてコンテナを配置する。
サービスディスカバリ/ロードバランシング
コンテナ増減した場合も、ルーティングできるように制御する。
また、アップデート時や障害時にコンテナを切り離したりもする。
いろいろデキるんだねー
他にも設定ファイルとかログを管理したり、コンテナのアップデートをいい感じにやってくれたりするよ
Kubernetesのインストール
Kubernetesを構築する方法はいくつかあるんだけど…その前にどういう構成になってるか整理してみよう

うわぁ、なんかフクザツそう…dockerみたいに一つのサーバじゃないから、インストール作業だけでひと苦労…?
コンテナを実際に動かすNodeサーバと、Nodeたちを管理するMaster Nodeサーバ、そしてクライアントからMaster NodeにAPIを送るCLI、という感じの構成だね
これもdockerでカンタンにできないのかなぁ…
構築ツールは色々作られていて、そういうのもあるみたい。でもまぁ、目的によって使うツール・サービスが変わってくるね
プロダクション環境として構築
自前で全部構築するか、GCP/Azure/AWSといったパブリッククラウドのマネージドサービスを利用する方法があるよ
自前の場合、公式の構築ツールkubeadmを使う感じ
やっぱりムズいー!クラウドのサービス使って全部丸投げしたい!!
自前運用も大変って聞くし、全然アリだよね…
動作確認・個人開発環境
1台のホスト上に構築
minikubeは1つのホスト上に仮想マシンを立てる方法で、他の2つはコンテナを利用する方法。分かりやすいリンク貼っておきます…!
Minikubeを使用してローカル環境でKubernetesを動かす - Kubernetes
microk8s を使って3分でローカル Kubernetes 環境を構築する - mhiro2 - Medium
お手軽Kubernetesクラスタ作成ツール "kind"の紹介 - Cybozu Inside Out | サイボウズエンジニアのブログ
たすかる!
webサービスを利用
webブラウザ上でお手軽に動作確認できるから、勉強はこっちで試しながらが良さそうね
ブラウザだけで3分でKubernetesが試せるKatacoda - Qiita
そうしましょう…!
つづく。
マンガっぽくDockerを布教してみる
Dockerとの出会い

という訳で、dockerについて教えるよ
はいっ♪さすが、ふわ先輩!頼りになる〜
この記事の目的
dockerを触ったことないけど、気になっている人向け。
この記事をさらっと読んで、ざっくり雰囲気が伝われば良いと思っている。
Dockerについてざっくり
Linuxのコンテナ型仮想化技術を使ったソフトウェア。
Dockerをインストールした環境上で、アプリやファイルをまるっとパッケージしたものを
コンテナとして動かせる。
うーん?コンテナにすると何が嬉しいんですか?
コンテナは1つのOS上で他プロセスと分離された領域で動くから、別のアプリにも影響が無いの
じゃあインストール失敗してもやり直し放題!?助かる〜♪
VMと違ってOS(kernel)は共有だから、起動も早い
おおっ♪(かーねる?)
更にDockerが動いてる環境ならコンテナごと持ってきてそのまま動かせる!

早い(起動が)安い(構築コストが)うまい(効率がいい)ですね!
あ、うん…?
Dockerをインストール
Docker公式とか、他のブログとか参考にしてください!
(あ、丸投げした…)
日本語版ドキュメント: Docker のインストール — Docker-docs-ja 17.06.Beta ドキュメント
Dockerの使い方
コンテナを使う方法は大きく2つあるよ
①dockerコマンドでコンテナを起動
以下コマンドを実行すると、コンテナが起動してイメージに定義されたコマンドが実行される。
docker run -it <イメージ名>:<タグ名>
ふ〜ん、わかんないけど、docker runでイイってこと?
オプションは他にも色々あるけどね。ここで書いた<イメージ名>に対応するDockerイメージを元にコンテナが作られるよ
また、引数としてコマンドを指定すると、そのコマンドが優先的に実行される。
そして、コマンドの処理が終わるとコンテナは停止する。
# centOS7のイメージ上でbashが起動する。exitでコンソールを抜けるとコンテナは停止する。 # -itのオプションはコンテナ内のコンソールを操作するコマンドを実行する時に付ける。 docker run -it centos:7 /bin/bash # centOS7のイメージ上でechoが起動する。echoが処理が終わるとコンテナは停止する。 docker run centos:7 /bin/echo test > test
イメージ…コンテナとは違うの??
イメージは、変更することができないよう固められた、コンテナの元となるもの。
ローカルに無ければDockerHub(Docker社のホスティングサービス)からダウンロードされる。
そのイメージに変更可能な領域を加えたものがコンテナとして動く。

DockerHubにはOSSの公式イメージとか、個人が作成したものが登録されてるよ
なるほど!じゃあわたしが使いたいOSSのイメージがあれば、 インストールの手間が無くなるってコトね!
あれ…でもインストール後の設定とか、自作アプリとかは 結局コンテナ起動後に作業しないとダメ…?
そういう細かいことしたい時には、もう1つの方法、Dockerfile を使う手があるよ
②Dockerfileでイメージを作ってからコンテナを起動
Dockerfileにベースとなるイメージと、各種操作を定義することで オリジナルのDockerイメージを作成できる。
FROM python:3.7.4 ARG project_directory WORKDIR ${project_directory} COPY ./run.py RUN pip install flask sqlalchemy CMD ["python", "run.py"]
こんな感じで設計書を作ってdocker buildコマンドを実行したらイメージが作られるよ
# 最後の引数はdockerfileの置き場所を指定 docker build -t <タグ名> .
なんか色々書いてある…
まぁこれもまた色々文法があるんだけど…まずはこの3つを覚えたら大丈夫かな。
- FROM ベースとなるイメージ名を指定
- RUN イメージビルド時に実行するコマンドを指定
- CMD コンテナ起動時のコマンドを指定
ムズカシイけど、一回作っちゃえば手順書いらないっていうか、使い回しカンタンじゃん!!
そういうこと!楽したいよね!慣れてきたら続きは公式で!!
(徹底している…)
日本語版ドキュメント: Dockerfile リファレンス — Docker-docs-ja 17.06.Beta ドキュメント
portとvolume
なんとなくフンイキはわかった!さっそくコンテナ動かそ!
docker run -it centos:7 /bin/bash
ちなみにこのままだと外からコンテナ内のアプリとかファイルには アクセスできない
ええっー!?それじゃ意味ないんですけど!?
コンテナへのアクセスはポートフォワードでの橋渡しを定義する必要がある。
また、コンテナ内のディレクトリとホスト側のディレクトリを
共有することができる。

結果的にこういうコマンドで起動することになるよ
docker run -it -p 80:80 -v `pwd`:/work centos:7 /bin/bash
な、なんか長い…!これじゃあDockerfileだけじゃなくて コマンドもメモしておかないと、使い回せないね…
そんなギャルちゃんにオススメのツールがこちら!
?!
docker-composeがとても便利
起動するコンテナ毎にportやvolume、利用イメージを定義する。
version: "3.0" services: web: image: centos:7 ports: - "80:80" volumes: - "`pwd`:/work" command: "/bin/bash" # 以下、複数定義可
あとはこのコマンドを打つだけでコンテナが一気に起動するよ
docker-compose up
コマンドもスッキリだぁ!これならdockerfileとymlファイルさえあれば 必要な環境まるっと使い回せますね!
(スッ)
日本語版ドキュメント: Compose ファイル・リファレンス — Docker-docs-ja 17.06.Beta ドキュメント
わー
抱負
Kubernetesを勉強しながら記事にしたい!
pythonでDB操作
DBMSに依存しないDB操作プログラミング
SQLiteやMySQL, PostgreSQL, Oracle Databaseなど色々DBMSがあり、それぞれプログラムから使用する際はDBMS毎に異なったコーディングが必要。覚えきれない…。
そこで、オブジェクト指向マッピング(ORM)という技法を使えば、DBMS毎にコードを変える必要が無くなるのです!
pythonにはSQLAlchemyというパッケージがあり、それで実現できます。やったね!
ということで、これは是非身につけたい。
まずはSQLite用のコーディング
SQLite用に書くとこんな感じなります。
sqlite3はpythonに標準でインストールされていて、軽くて使いやすい。らしい。
import sqlite3 # DBのコネクションを生成 # :memory:を指定すると、DBがメモリ上に保存され、接続が終了すると消える。DBファイルに出力するときはファイル名を指定する。 conn = sqlite3.connect(':memory:') # DBを操作するためのカーソルを生成 curs = conn.cursor() # executeでSQLを実行 curs.execute( 'CREATE TABLE persons(id INTEGER PRIMARY KEY AUTOINCREMENT, name STRING)') curs.execute( 'INSERT INTO persons(name) values("Mike")' ) curs.execute( 'INSERT INTO persons(name) values("Nancy")' ) conn.commit() curs.execute('SELECT * FROM persons') # クエリ結果をコンソールに表示 print(curs.fetchall()) conn.close()
コンソールの表示結果は↓
[(1, 'Mike'), (2, 'Nancy')]
これがMySQLやPostgreSQLになるとまた別のパッケージをインストールして、そのパッケージの使い方に合わせたコーディングが必要。
SQLAlchemyを使ってみる
SQLAlchemyを使ってSQLiteのDBを操作するコーディングはこうなる。
import sqlalchemy import sqlalchemy.ext.declarative import sqlalchemy.orm # データベース接続のためのEngineオブジェクトを取得 engine = sqlalchemy.create_engine('sqlite:///:memory:') # Baseにオブジェクトを生成 Base = sqlalchemy.ext.declarative.declarative_base() # Baseに入ったオブジェクトのクラスを継承して、テーブルの定義クラスを作成 class Person(Base): __tablename__ = 'perons' # テーブルのカラムを定義 id = sqlalchemy.Column( sqlalchemy.Integer, primary_key=True, autoincrement=True) name = sqlalchemy.Column(sqlalchemy.String(14)) # 使用するデータベースのEngineをBaseに設定 Base.metadata.create_all(engine) # DBにアクセスするため、Engineのセッションを作成 Session = sqlalchemy.orm.sessionmaker(bind=engine) session = Session() # DBに追加するオブジェクトを作成し、セッションに追加 person1 = Person(name='Mike') person2 = Person(name='Nancy') session.add(person1) session.add(person2) session.commit() # クエリの結果全てをリストで取得 persons = session.query(Person).all() # リストの中身をコンソールに表示 for person in persons: print(person.id, person.name)
出力結果は↓
1 Mike 2 Nancy
UPDATEする時は次のように記述
# データを更新 # まずは更新対象のデータの1行目を取得 person3 = session.query(Person).filter_by(name='Mike').first() # データを書き換え、セッションに追加 person3.name = 'Michel' session.add(person3) session.commit()
ここで色々と疑問
ひとまず、使い方の流れを理解した。…が、ちょっといくつか分からないコードがある。 基礎的な話です。
分からないポイント
pythonのクラスとかその辺がまだ身に付いていない感じ。
1つ目
import sqlalchemy engine = sqlalchemy.create_engine('sqlite:///:memory:')
sqlalchemyをimportしてるんで、sqlalchemyていうモジュールがあって、その中でcreate_engine関数が定義されてるんですよね?
探してみた結果。
sqlalchemyパッケージ(フォルダ)があり、その配下のengineパッケージの__init__.pyの中に定義されていました。
つまり、普通に呼ぶときは
import sqlalchemy.engine engine = sqlalchemy.engine.create_engine('sqlite:///:memory:')
となるはず?これで実行しても同じ結果でした。
ここで気付いたのが、「あれ、importする時って、パッケージ名.モジュール名だよね?」
あー、__init__.pyだとモジュール名が省略されるということか。
なので、import sqlalchemyの一文で、sqlalchemy配下の__init__.pyが呼ばれる。
そこには
from .engine import create_engine, engine_from_config
と記述がある。
ここでengineが出てきました。でもこれはパッケージなので、またモジュール名が無い。
そして__init__.pyの中にcreate_engineがいる。
つまり、import sqlalchemyだけでその配下のengineパッケージの__init__.pyまで読み込まれるってことかー…。慣れないorz
はい、次
2つ目
Base = sqlalchemy.ext.declarative.declarative_base() … Base.metadata.create_all(engine)
この流れ…。
あるクラスのオブジェクトを生成して、そのクラスのインスタンスメソッドcreate_allが呼ばれてるんだろうか…でも間の.metadata.は何者か。
Base.metadataはBaseに入れたクラスオブジェクトで、そのインスタンス変数matadataにまたクラスのオブジェクトが入ってて
そのクラスがcreate_allを定義しているってことかな。
sqlalchemyのドキュメントで調べると、そのクラスはclass sqlalchemy.schema.MetaDataということになっているが、いない。
pythonista3アプリだと宣言箇所に飛べないから
探すのが大変…。(修行にはなりそう)
そして、sqlalchemy.sql.schemaにいたーーー!
実態はsqlalchemy.sql.schema.MetaDataでした。
なんで違うかと考えたところ、ドキュメントには「MetaData API」という文字があったんで、これはあくまでAPIとしてのマニュアルってことか。
ドキュメント上は、実態とか関係なしにモジュールの呼び出し方だけ記載してあるってことなんですねー。知らなかった。
ドキュメント(英語)ちゃんと読めって話ですが、今はまだ時間がかかりすぎると思うので、もうちょいスキル上がってから読みます! 一旦モヤモヤは落ち着いたので良しとしよう。
最後
Session = sqlalchemy.orm.sessionmaker(bind=engine) session = Session()
Sessionとsessionの違いとは…。
Sessionはクラスのオブジェクトが入ってるとして、sessionはそれをインスタンス化したものだよねきっと。
ドキュメントに
A configurable Session factory.
The sessionmaker factory generates new Session objects when called, creating them given the configurational arguments established here.
て書いてある。訳すと
設定可能なセッションファクトリ。
sessionmakerファクトリは呼び出されると新しいSessionオブジェクトを生成し、ここで設定された構成引数を与えられてそれらを作成します。
うん、それっぽい!(疲れてきた)
まとめ
なるほど、こうやってDBMSの種類に合わせたクラスの構造自体を作っていって、操作する時はその出来上がったクラスをインスタンス化して使うってことなんだなぁ。きっと。
今はそう理解しておこう…。またスキルが上がった時にさらに深掘りしたいと思います
詳しい人いたら是非指摘して欲しい!
プログラミング修行中
何にしてもプログラミング
インフラからフロントエンドまで、色々できるようになりたいとは言っても、まずはプログラミングスキルが無いと転職もできない、ということで力を入れないといけない。
アウトプットしていく
年末から時間を見つけては競技プログラミングの問題を解いていました。 数をこなすのはいいけど、自分のコードを見直したり、レベル高い人のコードと比べたりして復習の時間も必要…ということでアウトプットしながら頭の中を整理していく習慣をつける!
今回のアウトプット
競技プログラミングとは別で、Udemyで購入したシリコンバレー流のpythonコードスタイルを学ぶ!という動画も視聴進めています。そちらもかなりインプットが溜まっているので、整理整理。
CSVファイルの読み込み、書き込み
よく使いそうな処理をピックアップして書いてみます。
configファイルでcsvファイルパスを指定
configparserパッケージを使ってみます。
まずは、config.iniファイルを作成。
import configparser # ConfigParserクラスのオブジェクトを作成 config = configparser.ConfigParser() # 辞書形式でカテゴリと各要素を指定 config['CSV_FILE'] = { 'path': 'tmp/', 'name': 'counter.csv', } # config.iniファイルを新規作成し、writeメソッドにオブジェクトを渡し書き込む # ファイルのclose忘れを防止するため、withステートメントを使用している with open('config.ini','w') as config_file: config.write(config_file)
これで出来上がったconfig.iniファイルの中身が以下。
[CSV_FILE] path = tmp/ name = counter.csv
csvファイルの存在を確認、無ければ新規作成
CsvModelというクラスを作って、オブジェクト生成時に存在確認する。
class CsvModel(): def __init__(self): self.csv_file = self.get_csv_file_path() # csvファイルが存在しなかったら新規作成 if not os.path.exists(self.csv_file): pathlib.Path(self.csv_file).touch() self.header = [CSV_HEADER_NAME, CSV_HEADER_COUNT] # csvデータの格納領域を作っておく。 # (keyがない場合、int型のデフォルト値(0)が設定される、defaultdictオブジェクト) self.data = collections.defaultdict(int) self.load_data()
get_csv_file_pathメソッドでは、configparserを使ってconfigファイルの内容を読み込み、csvのパスを返すようにしている。
def get_csv_file_path(self): config = configparser.ConfigParser() config.read(CONFIG_FILE) return config['CSV_FILE']['path'] + config['CSV_FILE']['name']
また、load_dataメソッドでは、既にcsvファイルが存在していた場合、オブジェクト生成時にcsvの内容を読み込む。
def load_data(self): with open(self.csv_file, 'r+') as csv_file: reader = csv.DictReader(csv_file) for row in reader: self.data[row[CSV_HEADER_NAME]] = int(row[CSV_HEADER_COUNT]) return self.data
csvファイルにデータを書き込む
csvパッケージのDictWriterを使うと簡単!
def save(self): with open(self.csv_file,'w+') as csv_file: # DictWriterを使うと、辞書形式でcsvファイルに書き込める writer = csv.DictWriter(csv_file,fieldnames=self.header) writer.writeheader() for name, count in self.data.items(): writer.writerow({ CSV_HEADER_NAME: name, CSV_HEADER_COUNT: count })
csvファイルに書き込むデータを作成
csvのカラムNAMEを指定したら、対応するCOUNTカラムの値が増えていくメソッドを作成。
def increment(self, name): self.data[name] += 1 self.save()
ではこれを使ってcsvファイルに書き込もう!
import csvmodel csv_file = csvmodel.CsvModel() csv_file.increment('rabbit') csv_file.increment('cat') csv_file.increment('dog') csv_file.increment('rabbit')
結果は…
NAME,COUNT rabbit,2 cat,1 dog,1
できました!
動画の演習内容をもとに自分なりにカスタマイズしたけど、色々と歪な設計になってしまったような気がするorz
オブジェクト指向的なコーディングも鍛えなきゃ…。
一応、読み込みも確認のため、別のオブジェクト生成してみる。
csv_file2 = csvmodel.CsvModel() csv_file2.increment('rabbit') csv_file2.increment('cat') csv_file2.increment('rabbit') csv_file2.increment('rabbit')
↓
NAME,COUNT rabbit,5 cat,2 dog,1
あってます。
家族が増えました
全然関係ないですが、癒しのため。

新たな危機感
再起動中…
4ヶ月振りに更新です。 なんとなくモチベ下がってからそのままゲームにハマり、仕事も忙しくなり、なんとなく充実して危機感も薄れてしまったのかなーと分析…。
9月の成果物です

そしてゲームクリアに60時間。
ゲーム楽しいけど時間が吸い取られます…。
目標を再設定
いつか仕事で使えるよう、プログラミングのスキルアップを目指し勉強してきたけど、自分と会社の方針のギャップが広がっているのを感じた11月末。
この会社ではエンジニアとしての仕事は出来ない!と判断し、次のキャリアに向けて どこに行っても戦えるようなスキルを身につける!というのが新たな目標です。
身につけたいスキル
フロントエンドからバックエンド、インフラ周りも触れるのが理想。 (フルスタックエンジニアと言うらしい)
vue.js
javascriptのフレームワーク。最近のトレンドらしく、フロントエンジニアの求人を見ているとよく見かけるので、抑えておきたいなと思っています。…正直javascriptのフレームワークの違いが良く分からないので、そこも勉強!
ここで勉強中。
はじめてのVue.js 3 入門!jQuery を使わないウェブ開発 - 導入からアプリケーション開発まで体系的に学ぶ | Udemy
python
バックエンドのロジックは書けるようになっておきたい。Javaは実戦経験無いけどそれなりにできる(ハズ)なので、pythonを継続で。 ロジックの修行として競技プログラミングを勧められたので、↓のサイトでちまちまやってます。
AtCoder:競技プログラミングコンテストを開催する国内最大のサイト
上位プログラマーのコード見てると心が折れそうなほど理解できない…。
Docker + Kubernetes
仮想マシンとは違う、一つのマシン上にアプリ+インフラを仮想的な領域(コンテナ)で 実行することができる技術を便利に活用できるアプリケーションたち。 まだまだこいつが何者なのかは理解できてません。 ↓の書籍で勉強中。

AmazonWebService
有名なクラウドサービスはいくつかありますが、ここに勝てるものはもういないのでは…。 簡単に仮想マシンやネットワーク、DBも1人で構築出来てしまう。 インフラでは必須のスキルだと思ってます。
動画見ながら、一年間の無料枠+一部有料機能使って勉強中。
https://www.udemy.com/aws-14days/learn/v4/content
3月末までにやること
インフラからフロントエンドまで、一通り作ってみようと思います。
…さすがに独学で一人だと厳しいので会社の先輩に協力もらいながら 何か便利なWebサービスを作って、公開、運用するのが目標です!
それを武器に、次のステップに進みたい。