スクレイピングに挑戦
アウトプットが渋滞中
週一回の更新を目標にしていましたが、追い付かなくなってきました。
仕事の方も新しい試み(自分の中で)をやっていて、そちらも覚えるものが多く大変…。スクラムや継続的インテグレーション(CI)などなど。
ただ、今までの仕事の仕方に比べると楽しいので苦ではないですけどね。仕事を楽しいと思う日が来るとは…!
自己学習では、自分が使いたいアプリを作るために必要なスクレイピングという技術について勉強中。 その経過について書きながら、頭の中を整理したい。
スクレイピングとは
WebページのHTML構造を解析し、任意の情報を抽出する技術です。 まず第一の目標として、市の施設予約システムからテニスコートの空き情報を取得するところまで作っていこうと思います。
そこで、pythonを使ったスクレイピングに使えるライブラリは次の2つ
urllib
URLを扱うライブラリ。 主に、URLを指定してリクエストを送信し、レスポンス情報を取得します。 その情報から、HTMLの要素を取り出したりするのに使います。 ただ、urllibよりはrequestsというライブラリの方がより高水準で使いやすく、お奨めらしい。
Beautiful Soup
面白い名前のライブラリ。「ふしぎの国のアリス」の中で出てくる詩が由来らしい。今度調べてみよう…。 HTMLを渡すと解析してくれます。
とりあえずやってみる
まずは小手調べに、自分が利用しているシステムのトップページのURLを指定して「title」要素を抽出してみる。
from bs4 import BeautifulSoup import urllib.request as req # URLを指定(一応マスキング) url = "https://xxxxxxxxxxxxxxxxx" # URLを開き、レスポンスを取得 res = req.urlopen(url) # レスポンス情報からHTMLを解析 soup = BeautifulSoup(res, "html.parser") # "title"要素を抽出 title = soup.select_one("title").string print("title = ", title)
結果は↓
title = 施設予約システム
こうでました!
あとは、select_one("title")で引数として渡している「title」の部分を他の要素で指定してあげれば割とすぐできるのでは?
…この結果を得られた時はそう思っていました…。
JavaScriptの壁
抽出したい対象の要素を知るために、ターゲットとなるシステムのHTML構造を見てみます。
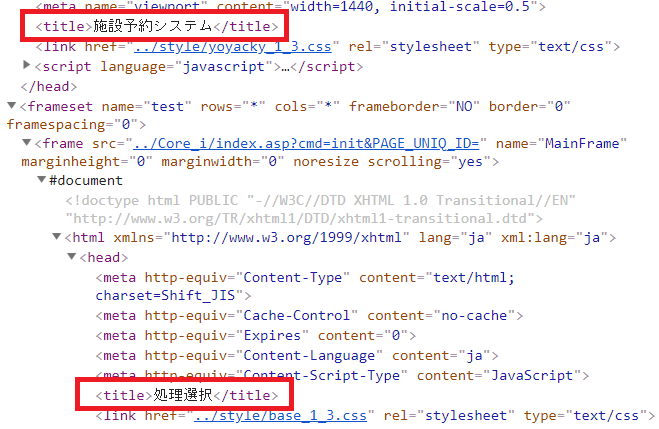
さっきは「施設予約システム」が抽出されたので、上の「title」が取れていたようです。 frame内の「title」を取るには、frame要素のsrc属性に指定してあるURIをくっつけたら良い…?
title = 表示できません
うーむ、URLをブラウザで直打ちするとタイトルが「処理選択」になるから、title要素もそうなってるハズなのに違う文字列が抽出されるのは何故だ…。
Beautifulsoupで解析した結果を以下のコードで表示して、HTML構造がどうなっているか見てみよう。
print(soup.prettify())
その結果を抜粋
<html> <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <meta content="no-cache" http-equiv="Cache-Control"/> <meta content="0" http-equiv="Expires"/> <meta content="ja" http-equiv="Content-Language"/> <title> 表示できません </title> <link href="../style/yoyacky_1_3.css" rel="stylesheet" type="text/css"/> <script language="javascript"> function Window_OnUnload(){ } </script> </head> <body bgcolor="#FFCC99" link="#000000" onunload="Window_OnUnload()" text="#000000" vlink="#000000"> </body> </html> <!--<font style="font-size:13pt;">--> <font class="SerchMiddleBold_font"> 接続が制限時間切れです。 <br/> ブラウザを閉じて処理をやり直してください。 <br/> <br/> 閉じるボタンが使用できない場合は、 <br/> ブラウザの閉じるボタンを使用して画面を閉じてください。 <br/> <input alt="この画面を閉じる" name="btn_close" onclick="window.top.close();return false;" src="../image/window_close.jpg" type="image" value="閉じる"/> </font>
表示できなかったパターンのHTMLが返ってきている。 body要素の属性にonloadでJavaScript指定してたりするから、画面操作しないとダメなんだろうか…。
JavaScriptも慣れてないから時間かけないとと厳しいなぁ。
次のアプローチ
このような場合のアプローチとして、Webブラウザ経由でのスクレイピング方法もあります。 そこで使えるのが、Webブラウザを自動操作させるSeleniumと、画面無しでコマンドラインから利用できるWebブラウザのPhantomJS!
Seleniumは今仕事でも使おうとしているし、一石二鳥! という訳でまたインプットのお時間が始まります。先は長そうだ。
RedisとBootstrapとGitHub
役立つオープンソースソフトウェアたち
Djangoのフレームワークを使ってWebアプリを作ってきましたが、これで捗るのはWebアプリの基本的な部分のみ。ただそれだけでも自分がコーディングする量は大幅に少なくなり大助かりですが!
今回のアプリでは、その他にもRedisを使ってデータを保存したり、Bootstrapを使ってページのデザインを綺麗にしたりと…世の中にはこんなに便利なソフトウェアやフレームワークがあったのかとビックリ。
プログラミングを勉強する!と言いながら始めましたが、実際、基本的な文法や標準ライブラリの使い方を覚えた後、こういったものを使い始めてからが本番なんだなーと感じているところです。
今回使った便利なツールたち
ライブラリやフレームワーク、OSS(オープンソースソフトウェア)やWebサービスなどなど色々な言葉はありますが、ひっくるめてツールと呼ぶことにします。ちょっと脳のメモリが不足気味…。
Redis
インメモリDBという種類のデータベースで、メモリ上にデータを格納するためRDBよりも高速にアクセス可能。永続性もあるらしい。 キー・バリュー型で、キー(key)を指定してバリュー(value)を取り出すシンプルな構造。
↓のように、手札の情報や所持金、ベット額を保存するのに使っています。

Bootstrap
Twitter社が開発した、CSSデザインのフレームワークらしい。 CSSのクラスが準備されていて、HTMLファイル内でクラスを指定すると、自分でCSSをコーディングすることなく見栄えがいい画面を作ることが可能!
↑に貼った質素な画面が、少しのコーディングで↓のようになります!これはすごい。(カードは画像ファイルです)

GitHubとGist
GitHub
GitHubは開発者向けのWebサービスで、無償でソースコードを格納するリポジトリを作成し、公開できるものです。OSSもこのサービス上にリポジトリが公開されていて、世界中の開発者達が一緒に開発したりできるという素晴らしいサービス。開発者達のSNSという表現をよく聞きます。
僕もアカウントを作ってみました。 メニューが全部英語なので、慣れるまで時間かかりそう…。
Gist
これが地味に役に立ちました。
今回、ブラックジャックのアプリ部分はiOSのpythonistaというアプリでコーディングしていて、WebアプリはPCで仮想OS上のエディタでコーディングしていました。

そこで、iphone→PC間のソースの受け渡しがめんどくさいなーと思ってpythonistaをポチポチしていたところ、GitHubのキャラクターっぽいシルエットを発見!

そこからGistにアップロードして、仮想OSからgit cloneしてソースをゲットするという技を身に付けることができました!
(↓のリンクから見れます)
広がっていく風呂敷
pythonでアプリを作る、というところから様々なツールを知ることができましたが、まだまだ使えるとは言えないレベル。自分が使いたいアプリを作る段階で、こういうツールを選定し、実装していくことで自分のものにしていきたい!と思った1週間でした。
Web画面の作り方
フレームワークの流れ
覚えたこと。 DjangoでのWebアプリ画面の作り方。
templatesディレクトリ配下にWeb画面の基礎部分となるhtmlファイルを作成する。htmlファイルに対するhttpリクエストの対応を
view.pyに記述する。対象のhtmlファイルが呼ばれる際のURLパターンを
urls.pyに記述する。
htmlファイル
記述としては↓のような感じ。(body部を抜粋)
<body> <form action="" method="POST" > {% csrf_token %} <p>記号<br> <select name="suit"> <option value="H">Heart</option> <option value="D">Dia</option> <option value="S">Spade</option> <option value="H">Clov</option> </select> </p> <p>数字<br> <select name="rank"> {% for i in rank_list %} <option value={{i}}>{{i}}</option> {% endfor %} </select> </p> <p> <input type="submit" value="送信"> </p> </form>
画面はこうなる。
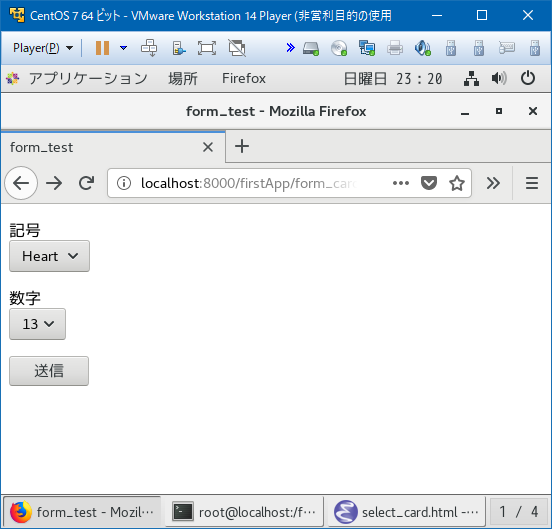
通常のhtmlの記述に加えて、{% %}で囲まれた部分にDjangoが用意したpythonっぽいロジックを記述できたり、view.pyとの変数のやり取りができたりします。
なお、templatesディレクトリ自体をDjangoが認識するために、setting.pyに今回作成したアプリの情報を記載する必要がある。
INSTALLED_APPS = [
'firstApp', #←これ#
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
view.py
記述はこんな感じ。
def form_card(request): if request.method =='GET': rank_list=[] for i in range(1,14): rank_list.append(str(i)) dictionary = {'rank_list':rank_list} dictionary.update(csrf(request)) return render(request, 'select_card.html', dictionary) if request.method == 'POST': suit = request.POST['suit'] rank = request.POST['rank'].zfill(2) dictionary = {'suit':suit, 'rank':rank} print(suit,rank) return render(request, 'display_card2.html', dictionary)
form_card関数が呼ばれたら、この処理が動く。
最終的にはrender関数で遷移先のhtmlファイルを決定し、dictionaryの部分にhtml内で使用する変数などなどを格納して受け渡しする。
ちなみに、dictionary.update(csrf(request))はDjangoが用意してくれているセキュリティ対策で、CSRF(クロスサイトリクエストフォージェリ)という攻撃を防ぐ機能を準備してくれている!
フレームワークって…いいね…。
urls.py
正規表現を使って、URLのパターンと、呼び出す関数の紐づけを行う。
urlpatterns = [
url(r'^form_card/$',views.form_card),
]
ここで記述する関数名と、view.pyに定義した関数名が違って何度もDjango先生に怒られました…。そして削られていく時間。
ちなみに送信ボタン押すと
対応するトランプのカードが表示されます。
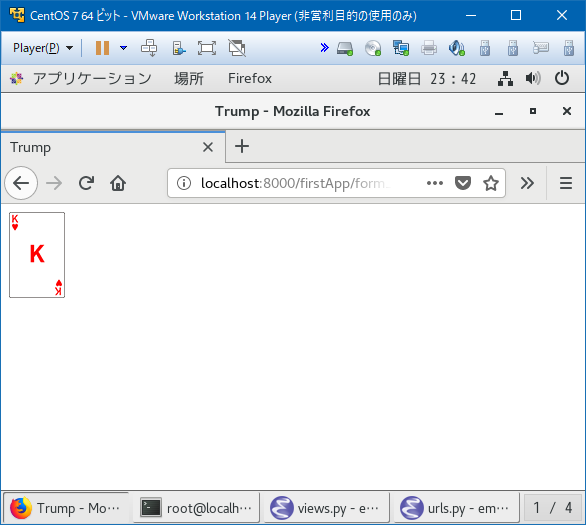
画面作成の基本的な流れはこんなところですかね。 次はDjangoでデータを保管したりする動作を覚えて、最後にブラックジャックを動かす!
…もうちょっと進めるペース上げたいけど、8月、9月は誘惑が多くて更に時間が削られることが想定されます。
- 8月~9月末までの誘惑
- 9月末~の誘惑
これらの壁をどう乗り切って行くかが鍵。 目標を見失わないようにせねば。
Djangoに触れてみる
再スタート
ひとまず心のモヤモヤも晴れ、やっと本筋に戻ることができました。心なしか、以前よりテキスト読みやすくなった気がします。
たぶん気のせい。
仮想OS上でWebサーバを動かす
閑話休題(使ってみたかっただけ)
3週間も経ってどこまでやったかあやふやですが、確かWin10のPC上の仮想マシンにCentOS7をインストールするところまでやっていました。
Webサーバソフトをインストール
CentOSにWebサーバ機能を持たせます。 Webサーバといえば、apacheが有名で、今読んでいるテキストもそれを導入しています。
しかし最近はnginx(エンジンエックス)というソフトが普及してきているらしく、今後主流になりそうなので、こちらを入れてみました。
apacheには「C10k問題」という、1つのWebサーバにクライアントが1万台接続すると、動作が重くなってしまう問題があります。
その点nginxは軽量でかつ1つのプロセスで複数のリクエストを処理する「イベント駆動モデル」であり、クライアント台数が1万台を超えても余裕で動く。
…という特徴があるので、ユーザ数が多いWebシステムにおいて利点があります。
そんなでかいシステム作れませんが、流行りに乗っておきたい。
インストール自体は簡単で、CentOSに含まれているyumコマンドで一発!
- rootユーザで、
/etc/yum.repos.d/nginx.repoファイルを作成し、以下の内容で保存。これで、yumコマンドで参照するリポジトリが追加される。[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/mainline/centos/7/$basearch/
gpgcheck=0
enabled=1
- そして、
yum install nginxコマンドを実行!終わり! - 一応、バージョン確認コマンド
nginx -vで、インストール成功しているのを確認。
やっとDjango
やっとDjango(ジャンゴ)に戻ってきました。 Webサーバの準備はできたので、そこに乗せるWebアプリを作っていきます。
pythonをインストールした際についでに入っているpipツールでDjanoをインストールできました。yumのpython版ってところですかね?
プロジェクト作成
ここから、Webアプリ開発に便利なフレームワークを使っていきます。
django-admin startproject プロジェクト名のコマンドでプロジェクト用ディレクトリが作成され、その中に部品達が生成されます。
中でもmanage.pyというpythonファイルの部品が、アプリを作るための各種雛形ファイルを作ってくれたり、開発用の簡易サーバを起動したりしてくれるみたいです。
python manage.py runserverでサーバ起動。(ポートは8000番)python manage.py startapp アプリ名でアプリ用雛形作成。
Webアプリ用の雛形ファイル
主要なものをメモメモ。
view.py
画面に何を表示させるか、どんな処理をするかを記述する。
apps.py
アプリケーションの設定を記述する。
models.py
データベース関係のファイル。
admin.py
管理画面の設定を記述する。
urls.py(これは自作)
URLと、呼び出される処理の関係を記述する。
今週はこんなところ。
今後の予定
今読んでいる本をマスターするまでは、と思っていましたが衝動買いしてしまった。

以前の投稿で書いた、直近で欲しいアプリを作るための技術「スクレイピング」(Webサイトのデータを取得するもの)について記述があったのでつい…。
積み本が増えないように早く進めなければ…。
「理解する」について理解していく
ブログを始めて1ヵ月
経ちました。早すぎますね…。
一番のメインテーマである、プログラミングスキルアップの前に立ちはだかった壁、「理解するということ」について、更に、理解へ繋がりそうなインプットを得たので、それをアプトプットしたいと思います。
新たなテンプレート構築のための「技」
カッコイイ見出しにしてみました。
前回の投稿で、自分が理解するために、事象をテンプレート化して脳内に保管する、という概念を学びました。
そのテンプレートを新たに構築するためには、「仮説立証」が有効という話でしたが、そのやり方を深堀りします。
インプットにした書籍
ビジネスマンのための「発想力」養成講座 (小宮一慶の養成講座) (ディスカヴァー携書)
ビジネスマンのための「読書力」養成講座 小宮流 頭をよくする読書法 (ディスカヴァー携書)
経営コンサルタントの小宮一慶さんの本です。 会社の先輩から4冊借りて、1週間で上記含む3冊を一気に読みました。
前回の本もですが、まさか自分がこんなに必死に自己啓発の本を読むことになるとは思いませんでした…。それだけ必要に駆られているということでしょう。
仮説検証することで、理解する
畑村さんの本の概念をベースに、小宮さんの本のテクニックを加えることで自分なりに解釈した内容を記します。
1.「関心」からの「疑問」
ある事象に対し、理解しようとする際に自分が持つ知識(テンプレート)を当てはめるにしても、まずはその事象に関心を持つこと!
そして、関心を持った上で、「何故そうなっているのか?」と疑問を持ってみます。
疑問も持たずに読み進めれば、これまでのように「理解したつもり」になってスルーしてしまいます。
2.「疑問」に対し「仮説」を立てる
疑問を持つことで、それが自分のテンプレートのどれに当てはまるか考え始めます。 ここで、重要なのはそのテンプレートを当てはめた理由が自分の中で論理的に説明できること!
What(何が)、Why(なぜ)、How(どのようにして)そうなっているのか。
論理的でなければ、そのテンプレートの「構造」が成り立たないはずなので、それもまた「理解したつもり」になっているのです。
3.実際に動かし・観察することで「検証」する
自分が論理的に考えた仮説が合っているか否か、検証します。 その結果を踏まえ、仮説が正しければそのままの「構造」で、間違っていればを「構造」を修正した上で、自分の中で新たなテンプレートが構築されます。
それが「理解する」ということかなと思いました。
書いてあることの理解を深めるために
上記の、「関心→疑問→仮説→検証」を回しながら読み進めることが重要です。 それにより、書いてあることの論理的な「構造」が分かり、「構造」が分からなければ、それを構成する「要素」が何なのか知ることで、また新たなテンプレートとして自分の理解につながります。
という仮説を立てました
この自分なりの解釈もまた「仮説」ということです…!
本に書いてあることを鵜呑みにするだけでは理解出来たとは言えない!ということですね。 これが今まで出来ていませんでした…。
そういえば、僕が通っていた大学の教授が「教科書に書いてあること(数式)を信用するな。自分できちんと検証しろ。」と仰っていたのを思い出しました。10年近く前のことですが、今になって漸く分かった気がします。
「理解する」って何!
二歩下がる
仮想サーバの構築+Djangoの導入を進めているうちに問題が発生。
手順通りに進まない…。
書いてあることは理解しているつもりだけど、上手くいかない。
仕事でも似たような状況になることは多々あったのですが、その時は「そういうものだ」と思い込み、深く考えないようにしていました。
しかし最近になってようやく自覚しました。
今まで、理解したと思っていたが、理解した”つもり”になっていただけだったということです。
どういう状況かと言うと…
資料を読み込み、ポイントになりそうな部分をピックアップし、まとめる。そこまでは良いのですが、その後、他者へ説明しようとすると…できない。言葉が詰まる。質問に回答出来ない。
他者に説明できるくらいに理解しなきゃ…とは思いますが、でも今のやり方ではダメだよなぁ…と悩んでいた所
…そもそも、理解するってどういう状態?
と考えるようになりました。
そこで見つけたのが、この本です!
")
ズバリなタイトルで目に留まりました。
この本について
工学者で東京大学名誉教授の、畑村洋太郎さん著作。「失敗学」という学問の提唱者で有名な方の本でした。
2005年に出版された本ですが、これは自分の悩みにマッチしているし、有名な方の本だし、信頼できそうだ!という単純思考で即買い。
学べたこと
ひとまず1週間弱で一通り読み、分かった事をここに記します。
「わかる」とはどういうことか?
人が「わかった」と感じる時、以下の3パターンの事が脳内で判断されているのです。
- 「要素」の一致
- 「構造」の一致
- 「新たなテンプレートの構築」
前提として
世の中の全ての事象は「要素」が組み合わさり「構造」化され、さらに「構造」が組み合わさることで成り立っています。
それらの「要素」や「構造」について、人は今までの経験の中で知識として蓄え、「テンプレート(雛形)」化して脳内に保管しています。
「要素・構造」の一致
上記1,2については、ある事象に対して、自分が持っている「要素」または「構造」のテンプレートとのマッチングを試み、一致させることで「わかった」と感じます。
「新たなテンプレートの構築」
自分が経験したことのない、新たな事象が発生した場合、自分が持っているテンプレートを組み合わせ、より近いものとマッチングさせることで「わかった」と感じ、それを新たなテンプレートとして保管します。
テンプレートに関し、面白い話がありました。
脳科学の分野で研究されている現象として、「脳神経の髄鞘化(ずいしょうか)」というものがあります。
これは脳神経の周りに鞘ができる現象で、これにより神経の情報伝達速度が一桁から二桁早くなるとのこと。
そこで、新たなテンプレートを作るということは、この「髄鞘化」そのものではないか、と著者の畑村さんは考えていました。
そう考えると、「理解したつもり」では新たなテンプレートも作られず、髄鞘化も起きないので、他者へ説明するときに言葉が出てこないのかも?というのも一理あるのではと思います。
つまり、理解をしていくためには
資料を読んだり、経験をする中で、それにはどんな「要素」が含まれ、「構造」化されているかを意識することで、テンプレートを増やしていくこと。
また、新たなテンプレートを構築する時には「仮説立証」のプロセスを踏む事が有効らしいので、まずは先に答えを知るのではなく、自分で考え、予想してみた上で実際に動かし答え合わせすること。
その他にも
「直観」と「直感」の違いや、暗記の良し悪し、定量化訓練などが述べられていたり、「あー自分はこういうタイプだなー、だから理解力が足りないのか…」と思える具体事例があったりして面白いので、興味がある方は是非読んでみてください。
また、今回の紹介ではごちゃごちゃしそうだったので「要素」「構造」って具体的にどういうことを指す?といったことは書きませんでしたが、その例も豊富にありますので…。
まだまだ一度読んだだけでは理解しきれないので、この本をバイブルとして、実生活に当てはめながら理解を深めていきたいと思っています。
ブログタイトル
ブログを始めるきっかけも、この投稿のきっかけも、自分自身のことを知ることができたからでした。(目標が無いから興味も持てない、理解したつもりになり説明ができない)
それにちなんで、ブログのタイトルは
[31年目のRealize]
にしました。
realizeの意味
〔頭で思考・理解して〕~に気付く、~を悟る、自覚する、実感する
また
〔夢・望ましい状況などを〕実現する
31年目の人生で新たに気づき・自覚したことを期に、目標を実現させたい、という意味を込めてみました。いい感じの単語ですね。馴染む馴染む。
以上!
pythonコーディングひと段落
次はWEBアプリ
さて、プログラミングの方も、ちまちま進めています。 前回紹介した本の、ブラックジャックをpythonで作るところまでは完了です。
とはいえ、コマンドラインのみで動く簡単なものですが。

[ H 7 ]とか[ D 5 ]というのは、それぞれハートの7、ダイヤの5といった表記です。
モヤっとコード
このプログラムはfor文やif文、リスト等が分かっていればすぐに作れるので、あまり躓くことはありませんでした。
関数についても、メインのモジュールに関数を直書きして、メイン関数の中で使う、という流れ。
クラスを作ってインスタンス化→インスタンスメソッドを使う、といった処理は無かったため、物足りない感じ…。
(クラスメソッドとかスタティックメソッドとかがまだ腹落ちしていないので…次の課題ですね)
そんな中でも、ちょっとモヤっとするコード(完全にマスターしたとは言い切れないもの)があったのでメモ。
いわゆるリスト内包表記
#デッキを作る
def make_deck():
rank = range(1,14)
suit = ('S','H','C','D')
deck = [(i,j) for i in rank for j in suit]
random.shuffle(deck)
return deck
deck=[(i,j) for...の部分ですね。
(i,j)というタプル(要素を変更できない配列)のリストを生成しています。
rankが1から13までfor文で回る間、それぞれS,H,C,Dがfor文で回る二重ループの表記。これで全ての組合せのリストとなっています。
こういうのサラっと書けるようになりたい。
複数の戻り値を格納
#勝敗の結果を判定
message, player_money = win_lose(dealer_hand, player_hand, bet, player_money)
print(message)
win_loseという関数で勝敗が確定し、表示する文字列と所持金の増減値を返します。
それらをそれぞれ、messageとplayer_moneyに格納しています。
これは便利ですが…その関数が何をどの順番で返してくるのか、注意しないとすぐにバグ化する予感。
そしてDjangoへ
ついつい心の中で「ディージャンゴ」って呼んじゃいますが、「ジャンゴ」なんですよね。なぜだ。
ここでWEBアプリを動かす為のサーバが必要になるのですが、現在はその環境を構築中です。
自宅にあるWindows10のノートPC上に、CentOS7の仮想サーバを構築し、そこにDjangoを乗せて見ようと思っています。
CentOS
Linuxを基本にしたOS(ディストリビューション)の1つ。いくつかある中で、結構メジャーに使われているらしい。これも使いながら勉強していきましょう…。
参考
所感
Djangoへの道のりはもうちょっと長かっ た…。